1. Unterrichtsblock
Inhaltsverzeichnis
>>>> Einleitende Aufgabe
Erstelle ein Worddokument mit dem Titel „Webentwicklung_Unterrichtsblock_1.docx“ mit der offline Version von Word. Speichere das Dokument im entsprechenden Arbeitsordner ab.
In dem erstellten Dokument speicherst Du die Rechercheergebnisse aus diesem Unterricht.
KI ist für die Recherchen in diesem Unterrichtsblock nicht erlaubt.
Einleitung – Was zeigt diese Grafik?
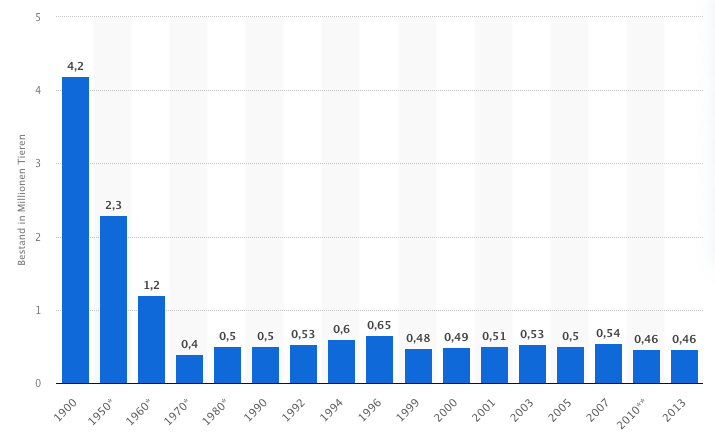
Aufgabe
- Beschreibe, wie sich die Zahlen über die Jahre verändert haben.
- Überlege, welche gesellschaftlichen, technischen oder wirtschaftlichen Gründe diesen Wandel erklären könnten.
Hinterlege die Rechercheergebnisse in dem zuvor erstellten Dokument „Webentwicklung_Unterrichtsblock_1.docx“ dort. Speichere das Dokument im entsprechenden Arbeitsordner ab.


Aufgabe
- Recherchiere den Begriff „Disruption“. Erkläre in eigenen Worten, was disruptive Veränderungen sind und wie sie entstehen.
- Betrachte die Bilder des Telefonbuchs und des Bestellkatalogs. Welche digitalen Alternativen nutzen wir heute stattdessen? Was hat sich dadurch im Alltag verändert – z. B. beim Suchen, Bestellen oder Kommunizieren?
- Recherchiere mindestens zwei Branchen, die von der industriellen Revolution betroffen waren. Beschreibe, wie sich Arbeitsweise oder Produktion verändert haben.
- Recherchiere mindestens zwei Berufsfelder, die von der Internet-Revolution betroffen waren. Erkläre, wie sich Aufgaben, Werkzeuge oder Anforderungen verändert haben.
Trage die Rechercheergebnisse im oben erstellten Arbeitsdokument „Webentwicklung_Unterrichtsblock_1.docx“ mit einer passenden Überschrift ein.
Internet
Der Ausdruck Internet ist ein Anglizismus. Er entstand als Kurzform der Bezeichnung interconnected networks (zusammengeschaltete Netzwerke) bzw. des daraus entwickelten Fachausdrucks internetwork, unter dem in den 1970er und 1980er Jahren die Entwicklung eines Systems zur Vernetzung von bestehenden, kleineren Rechnernetzen diskutiert wurde.
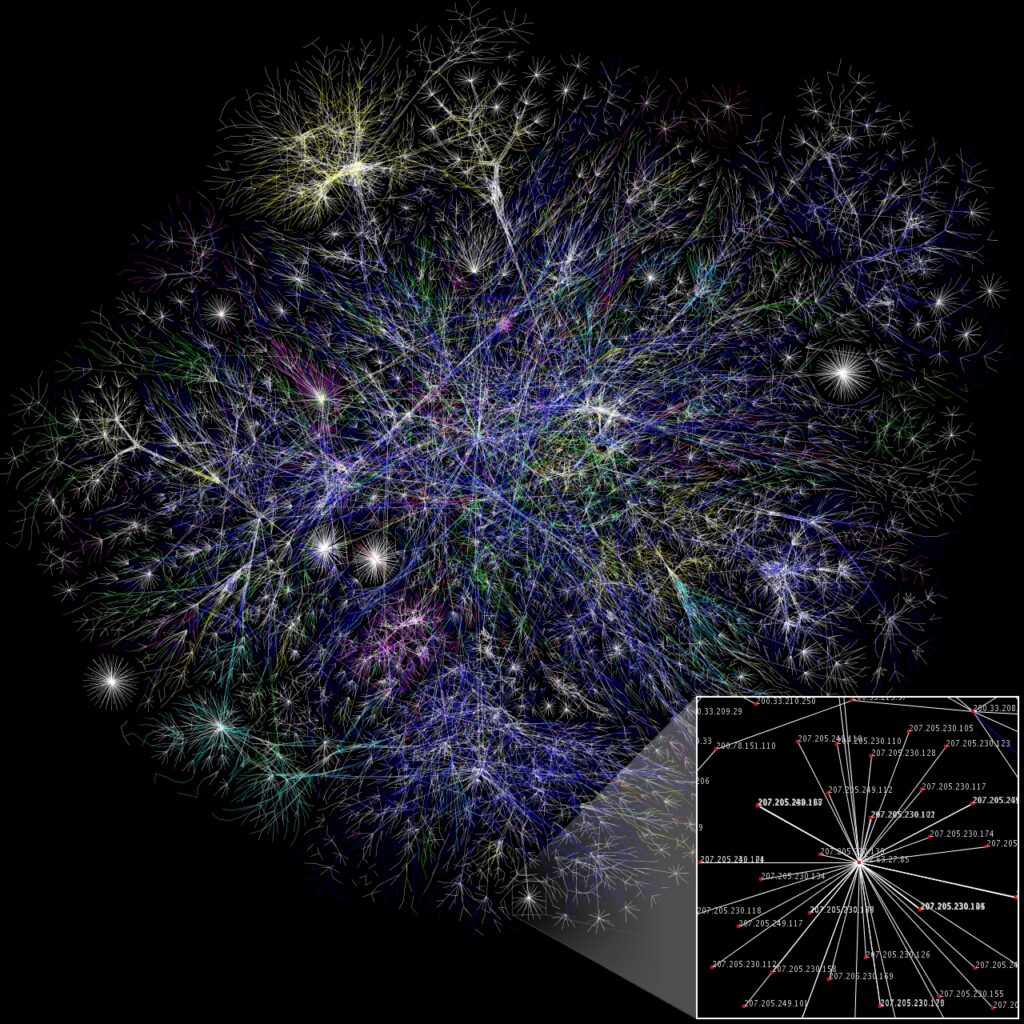
Aufgabe
- Was stellt das Bild dar? Beschreibe, was du auf der Grafik erkennst. Was könnten die Punkte und Linien bedeuten? Was zeigt die Vergrößerung unten rechts?
- Warum ist das Internet eine disruptive Veränderung? Erkläre, wie das Internet bestehende Strukturen verändert oder ersetzt hat – z. B. in Kommunikation, Wirtschaft oder Bildung.
- Welche bestehenden Systeme hat das Internet ersetzt? Nenne mindestens drei Beispiele aus dem Alltag und beschreibe, was heute stattdessen genutzt wird.
- Wie beeinflusst das Internet deinen Alltag? Überlege, in welchen Bereichen du täglich mit dem Internet zu tun hast. Was wäre anders, wenn es das Internet nicht gäbe?
Trage die Rechercheergebnisse im oben erstellten Arbeitsdokument „Webentwicklung_Unterrichtsblock_1.docx“ mit einer passenden Überschrift ein.
IP Adressen
Eine IP-Adresse (Internet Protocol) ist die eindeutige Identifikationsnummer, die jedem mit dem Internet verbundenen Gerät zugewiesen wird. Eine Definition einer IP-Adresse ist eine numerische Bezeichnung, die Geräten zugewiesen ist, die das Internet zur Kommunikation verwenden. Computer, die über das Internet oder über lokale Netzwerke kommunizieren, teilen Informationen mit IP-Adressen an einen bestimmten Standort.
IP-Adressen haben zwei verschiedene Versionen oder Standards. Die IPv4-Adresse (Internet Protocol Version 4) ist die ältere der beiden, die Platz für bis zu 4 Milliarden IP-Adressen bietet und allen Computern zugewiesen ist. Die neuere Internet Protocol Version 6 (IPv6) bietet Platz für Billionen von IP-Adressen, die neben Computern auch für die neue Art von Geräten verantwortlich sind. Es gibt auch verschiedene Arten von IP-Adressen, einschließlich öffentlicher, privater, statischer und dynamischer IP-Adressen.
Jedes Gerät mit einer Internetverbindung hat eine IP-Adresse, ob Computer, Laptop, IoT-Gerät oder sogar Spielzeug. Die IP-Adressen ermöglichen die effiziente Übertragung von Daten zwischen zwei verbundenen Geräten, sodass Maschinen in verschiedenen Netzwerken miteinander kommunizieren können.
Wie funktioniert eine IP-Adresse?
Eine IP-Adresse hilft Ihrem Gerät, unabhängig davon, auf was Sie auf das Internet zugreifen, um alle Daten oder Inhalte zu finden, die sich befinden, um den Abruf zu ermöglichen.
Häufige Aufgaben für eine IP-Adresse umfassen sowohl die Identifizierung eines Hosts oder eines Netzwerks als auch die Identifizierung des Standorts eines Geräts. Eine IP-Adresse ist nicht zufällig. Die Erstellung einer IP-Adresse basiert auf Mathematik. Die Internet Assigned Numbers Authority (IANA) ordnet die IP-Adresse und deren Erstellung zu. Der gesamte Bereich an IP-Adressen kann von 0.0.0.0 bis 255.255.255.255 reichen.
Mit der mathematischen Zuweisung einer IP-Adresse kann die eindeutige Identifizierung erfolgen, um eine Verbindung zu einem Ziel herzustellen.
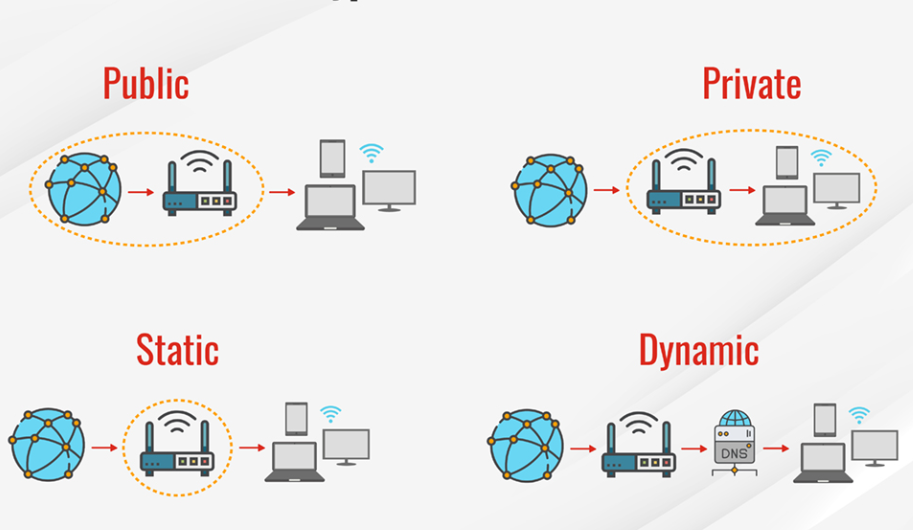
Arten von IP-Adressen:
Öffentliche IP-Adresse
Eine öffentliche IP-Adresse oder eine nach außen gerichtete IP-Adresse gilt für das Hauptgerät, das Personen verwenden, um ihr Geschäfts- oder Heim-Internetnetzwerk mit ihrem Internet Service Provider (ISP) zu verbinden. In den meisten Fällen ist dies der Router. Alle Geräte, die sich mit einem Router verbinden, kommunizieren mit anderen IP-Adressen über die IP-Adresse des Routers.
Die Kenntnis einer nach außen gerichteten IP-Adresse ist für Menschen von entscheidender Bedeutung, um Ports zu öffnen, die für Online-Gaming, E-Mail- und Webserver, Medienstreaming und das Erstellen von Remote-Verbindungen verwendet werden.
Private IP-Adresse
Eine private IP-Adresse oder eine interne IP-Adresse wird von einem Büro- oder Heimintranet (oder einem lokalen Netzwerk) Geräten oder vom Internet Service Provider (ISP) zugewiesen. Der Home/Office-Router verwaltet die privaten IP-Adressen der Geräte, die sich von diesem lokalen Netzwerk aus mit ihm verbinden. Netzwerkgeräte werden somit vom Router von ihren privaten IP-Adressen zu öffentlichen IP-Adressen zugeordnet.
Private IP-Adressen werden über mehrere Netzwerke hinweg wiederverwendet, wodurch wertvoller IPv4-Adressraum erhalten bleibt und die Adressierbarkeit über die einfache Grenze der IPv4-Adressierung hinaus erweitert wird (4.294.967.296 oder 2^32).
Im IPv6-Adressierungsschema hat jedes mögliche Gerät seine eigene eindeutige Kennung, die vom ISP oder der primären Netzwerkorganisation zugewiesen wird und ein eindeutiges Präfix hat. Private Adressierung ist in IPv6 möglich, und wenn sie verwendet wird, wird sie als Unique Local Addressing (ULA) bezeichnet.
Statische IP-Adresse
Alle öffentlichen und privaten Adressen sind als statisch oder dynamisch definiert. Eine IP-Adresse, die eine Person manuell konfiguriert und am Netzwerk ihres Geräts fixiert, wird als statische IP-Adresse bezeichnet. Eine statische IP-Adresse kann nicht automatisch geändert werden. Ein Internetdienstanbieter kann einem Benutzer eine statische IP-Adresse zuweisen. Die gleiche IP-Adresse wird diesem Benutzer für jede Sitzung zugewiesen.
Dynamische IP-Adresse
Eine dynamische IP-Adresse wird automatisch einem Netzwerk zugewiesen, wenn ein Router eingerichtet wird. Das Dynamic Host Configuration Protocol (DHCP) weist die Verteilung dieses dynamischen Satzes von IP-Adressen zu. Der DHCP kann der Router sein, der Netzwerken in einem Zuhause oder in einem Unternehmen IP-Adressen bereitstellt.
Jedes Mal, wenn sich ein Benutzer im Netzwerk anmeldet, wird aus dem Pool der verfügbaren (derzeit nicht zugewiesenen) IP-Adressen eine neue IP-Adresse zugewiesen. Ein Benutzer kann zufällig mehrere IP-Adressen über mehrere Sitzungen hinweg durchlaufen.
Was ist IPv4?
IPv4 ist die vierte Version der IP. Es ist eines der Kernprotokolle der standardbasierten Methoden, die verwendet werden, um das Internet und andere Netzwerke zu verbinden. Das Protokoll wurde 1982 erstmals im Atlantic Packet Satellite Network (SATNET) bereitgestellt, einem Satellitennetzwerk, das ein Segment der Anfangsphasen des Internets bildete. Sie wird trotz vorhandener IPv6 weiterhin verwendet, um den größten Teil des Internetverkehrs weiterzuleiten.
IPv4 ist derzeit allen Computern zugewiesen. Eine IPv4-Adresse verwendet 32-Bit-Binärnummern, um eine eindeutige IP-Adresse zu bilden. Es benötigt das Format von vier Zahlensätzen, von denen jeder von 0 bis 255 reicht und eine achtstellige Binärnummer darstellt, die durch einen Punkt getrennt ist.
IP-Adressklassen
Einige IP-Adressen werden von der Internet Assigned Numbers Authority (IANA) reserviert. Diese sind in der Regel für Netzwerke reserviert, die einen bestimmten Zweck im Transmission Control Protocol/Internet Protocol (TCP/IP) verfolgen, das zur Verbindung von Geräten verwendet wird. Vier dieser IP-Adressklassen umfassen:
- 0.0.0.0: Diese IP-Adresse in IPv4 wird auch als Standardnetzwerk bezeichnet. Es ist die nicht umleitbare Metaadresse, die ein ungültiges, nicht anwendbares oder unbekanntes Netzwerkziel angibt.
- 127.0.0.1: Diese IP-Adresse wird als Loopback-Adresse bezeichnet, die ein Computer verwendet, um sich zu identifizieren, unabhängig davon, ob ihm eine IP-Adresse zugewiesen wurde.
- 169.254.0.1 bis 169.254.254.254: Eine Reihe von Adressen, die automatisch zugewiesen werden, wenn ein Computer beim Versuch, eine Adresse vom DHCP zu empfangen, nicht erfolgreich ist.
- 255.255.255.255: Eine Adresse für Nachrichten, die an jeden Computer in einem Netzwerk gesendet oder über ein Netzwerk übertragen werden müssen.
Weitere reservierte IP-Adressen sind für die sogenannten Subnetzklassen vorgesehen. Subnetze sind kleine Computernetzwerke, die sich über einen Router mit einem größeren Netzwerk verbinden. Dem Subnetz kann ein eigenes IP-Adresssystem zugewiesen werden, sodass alle mit ihm verbundenen Geräte miteinander kommunizieren können, ohne Daten über das breitere Netzwerk senden zu müssen.
Der Router in einem TCP/IP-Netzwerk kann so konfiguriert werden, dass er Subnetze erkennt und dann den Datenverkehr an das entsprechende Netzwerk weiterleitet. IP-Adressen sind für die folgenden Subnetze reserviert:
- Klasse A: IP-Adressen zwischen 10.0.0.0 und 10.255.255.255
- Klasse B: IP-Adressen zwischen 172.16.0.0 und 172.31.255.255
- Klasse C: IP-Adressen zwischen 192.186.0.0 und 192.168.255.255
- Klasse D oder Multicast: IP-Adressen zwischen 224.0.0.0 und 239.255.255.255
- Klasse E, die für die experimentelle Verwendung reserviert sind: IP-Adressen zwischen 240.0.0.0 und 254.255.255.254
IP-Adressen, die unter Klasse A, Klasse B und Klasse C aufgeführt sind, werden am häufigsten bei der Erstellung von Subnetzen verwendet. Adressen innerhalb des Multicasts oder der Klasse D haben spezifische Nutzungsregeln, die in den Richtlinien der Internet Engineering Task Force (IETF) beschrieben sind, während die Freigabe von Adressen der Klasse E für die öffentliche Nutzung der Grund für viele Diskussionen war, bevor der IPv6-Standard eingeführt wurde.
Internetadressen und Subnetze
Das IANA behält bestimmte IP-Adressblöcke für kommerzielle Organisationen, Regierungsbehörden und ISPs vor. Wenn sich ein Benutzer mit dem Internet verbindet, weist ihm sein ISP eine Adresse aus einem der ihm zugewiesenen Blöcke zu. Wenn sie nur von einem Computer aus online gehen, können sie die von ihrem ISP zugewiesene Adresse verwenden.
Die meisten Haushalte verwenden jedoch heute Router, die eine Netzwerkverbindung mit mehreren Geräten teilen. Wenn also ein Router verwendet wird, um die Verbindung zu teilen, weist der ISP dem Router die IP-Adresse zu, und dann wird ein Subnetz für alle Computer erstellt, die sich mit ihm verbinden.
IP-Adressen, die in ein Subnetz fallen, verfügen über ein Netzwerk und einen Knoten. Das Subnetz wird vom Netzwerk identifiziert. Der Knoten, auch Host genannt, verbindet sich mit dem Netzwerk und benötigt seine eigene Adresse. Computer trennen das Netzwerk und den Knoten über eine Subnetzmaske, die die entsprechende IP-Adressbezeichnung filtert. Wenn ein großes Netzwerk eingerichtet wird, wird die Subnetzmaske bestimmt, die am besten zur Anzahl der benötigten Knoten oder Subnetze passt.
Bei IP-Adressen innerhalb eines Subnetzes wird die erste Adresse für das Subnetz reserviert und die letzte gibt die Broadcasting-Adresse für die Systeme des Subnetzes an.
IPv4 vs. IPv6
IPv4 war nicht in der Lage, mit der massiven Zunahme der Anzahl und des Spektrums von Geräten zurechtzukommen, die über Mobiltelefone, Desktop-Computer und Laptops hinausgehen. Das ursprüngliche IP-Adressformat konnte die Anzahl der erstellten IP-Adressen nicht verarbeiten.
Um dieses Problem zu lösen, wurde IPv6 eingeführt. Dieser neue Standard verwendet ein hexadezimales Format, das bedeutet, dass jetzt Milliarden von eindeutigen IP-Adressen erstellt werden können. Infolgedessen wurde das IPv4-System, das bis zu etwa 4,3 Milliarden eindeutige Nummern unterstützen könnte, durch eine Alternative ersetzt, die theoretisch unbegrenzte IP-Adressen bietet.
Das liegt daran, dass eine IPv6-IP-Adresse aus acht Gruppen besteht, die vier hexadezimale Ziffern enthalten, die 16 verschiedene Symbole von 0 bis 9 verwenden, gefolgt von A bis F, um Werte von 10 bis 15 darzustellen.
Wie finde ich meine IP-Adresse?
Windows-Computerbenutzer können ihre IP-Adresse suchen, indem sie „cmd“ in die Suchregisterkarte eingeben und die Eingabetaste drücken und dann „ipconfig“ in das Popup-Feld eingeben. Mac-Computerbenutzer können ihre IP-Adresse finden, indem sie in den Systemeinstellungen gehen und Netzwerk auswählen.
Um eine IP-Adresse auf einem Mobiltelefon nachzuschlagen, müssen Benutzer in die Einstellungen gehen und dann das WLAN-Menü und ihr Netzwerkmenü öffnen. Die IP-Adresse sollte je nach verwendetem Telefon im Abschnitt „Erweitert“ aufgeführt werden.
IP-Adresse vs. MAC-Adresse
Bei beiden IP-Adresstypen handelt es sich um eine eindeutige Kennung mit einem Anhang zu diesem Gerät. Der Hersteller einer Netzwerkkarte oder eines Routers ist der Anbieter der MAC-Adresse, während der Internet Service Provider (ISP) der Anbieter der IP-Adresse ist.
Der Hauptunterschied zwischen beiden besteht darin, dass die MAC-Adresse die physische Adresse eines Geräts ist. Wenn Sie fünf Laptops in Ihrem Heim-WLAN-Netzwerk haben, können Sie jeden dieser fünf Laptops in Ihrem Netzwerk über seine MAC-Adresse identifizieren.
Die IP-Adresse funktioniert anders, da sie die Kennung der Verbindung des Netzwerks mit diesem Gerät ist. Weitere Unterschiede sind:
- Eine MAC-Adresse ist eine 6-Byte-Hexadezimaladresse, während eine IP-Adresse eine 4- oder 16-Byte-Adresse ist.
- Eine MAC-Adresse befindet sich in einer Datenverbindungsebene, während sich eine IP-Adresse in einer Netzwerkebene befindet.
- Ein Drittanbieter hat Schwierigkeiten, eine MAC-Adresse zu finden, während er leicht eine IP-Adresse finden kann.
- MAC-Adressen sind statisch, während sich IP-Adressen dynamisch ändern können.
- MAC-Adressen und IP-Adressen sind notwendig, um ein Netzwerkpaket an ein Ziel zu bringen. Allerdings kann niemand Ihre MAC-Adresse sehen, es sei denn, sie befindet sich in Ihrem LAN
Was sind Sicherheitsbedrohungen im Zusammenhang mit IP-Adressen?
Eine Vielzahl von Sicherheitsbedrohungen bezieht sich auf IP-Adressen. Cyber-Kriminelle können Geräte täuschen, um entweder Ihre IP-Adresse preiszugeben und vorzugeben, dass sie Sie sind, oder sie verfolgen, um Aktivitäten zu verfolgen und auszunutzen. Online-Stalking und Social Engineering sind die beiden häufigsten Sicherheitsbedrohungen, die für IP-Adressen bestehen.
Einige der anderen Sicherheitsbedrohungen für eine IP-Adresse sind:
- Ermöglichen Sie einem cyber-kriminell, Ihre IP-Adresse zu verwenden, um Ihren Standort zu verfolgen.
- Verwendung Ihrer IP-Adresse, um Ihr Netzwerk anzuvisieren und einen DDoS-Angriff zu starten
- Verwendung Ihrer IP-Adresse zum Herunterladen illegaler Inhalte
5 Möglichkeiten zum Schutz der eigenen IP-Adresse
Es gibt mehrere Möglichkeiten, Ihre IP-Adresse vor Cyber-Kriminellen zu schützen. Einige dieser Optionen umfassen:
- Verwenden Sie ein VPN
- Nutzung eines Proxy-Servers
- Lassen Sie Ihren ISP dynamische IP-Adressen nutzen
- Setzen Sie eineNAT-Firewall ein , um Ihre private IP-Adresse zu verbergen.
- Das Zurücksetzen Ihres Modems kann Ihre IP-Adresse ändern.
Domain, URI, URL
1. Was ist eine Domain?
Die Domain ist der menschenlesbare Name einer Webseite – also die Adresse, die du in den Browser eingibst, um eine Seite zu besuchen. Sie ersetzt die technische IP-Adresse und macht Webseiten leichter auffindbar. Domains werden über das DNS-System (Domain Name System) in IP-Adressen übersetzt. Das heißt: www.beispielseite.de → 172.0.27.5 → So weiß der Browser, mit welchem Server er kommunizieren muss.
Beispiel:
www.beispielseite.de
Aufbau einer Domain:
| Bestandteil | Beispiel | Funktion |
|---|---|---|
| Subdomain | www. | Optionaler Zusatz, z. B. für Bereiche wie „blog.“ |
| Second-Level-Domain | beispielseite | Hauptname der Webseite |
| Top-Level-Domain (TLD) | .de | Länderkürzel oder Kategorie (z. B. .com, .org) |
2. Was ist eine URL?
URL steht für Uniform Resource Locator. Sie ist die vollständige Adresse einer abrufbaren Ressource im Web – z. B. einer HTML-Seite, eines Bildes oder eines Videos. Eine URL zeigt nicht nur auf eine Webseite, sondern kann auch auf Bilder, PDFs, Videos oder API-Endpunkte verweisen.
Beispiel:
https://www.beispielseite.de/produkte/index.html?id=123
Bestandteile einer URL:
| Teil | Beispiel | Funktion |
|---|---|---|
| Protokoll | https:// | Legt fest, wie die Daten übertragen werden (z. B. verschlüsselt) |
| Domain | www.beispielseite.de | Zielserver der Anfrage |
| Pfad | /produkte/index.html | Speicherort der Datei auf dem Server |
| Parameter (Query) | ?id=123 | Zusätzliche Daten für die Anfrage (z. B. Produkt-ID) |
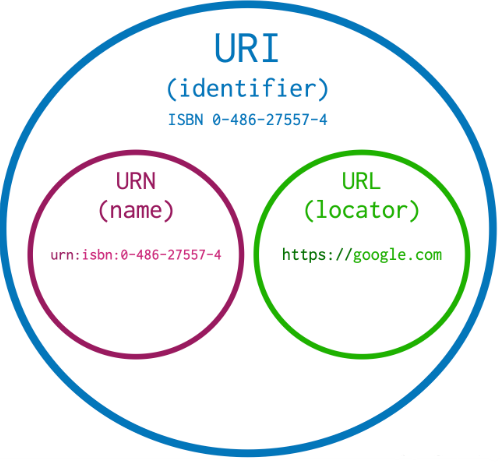
3. Was ist eine URI?
URI steht für Uniform Resource Identifier. Sie ist ein allgemeiner Begriff für jede Art von eindeutiger Kennung im Web. Eine URI kann eine URL sein – muss aber nicht.
Unterschied zur URL:
| Begriff | Funktion | Beispiel |
|---|---|---|
| URL | Zeigt auf eine abrufbare Ressource | https://www.beispielseite.de/index.html |
| URI | Identifiziert eine Ressource eindeutig – auch ohne Zugriffspfad | urn:isbn:978-3-16-148410-0 |
→ Jede URL ist eine URI, aber nicht jede URI ist eine URL.
Beispielhafte URIs:
mailto:info@beispielseite.de→ URI für eine E-Mail-Adresseurn:isbn:978-3-16-148410-0→ URI für ein Buchhttps://www.beispielseite.de→ URI und URL
Was ist ein URN?
URN steht für Uniform Resource Name. Es ist eine spezielle Form der URI (Uniform Resource Identifier), die eine Ressource eindeutig benennt – ohne zu sagen, wo sie sich befindet oder wie man sie abrufen kann.
Was macht ein URN?
- Ein URN ist wie ein fester Name für eine Ressource – vergleichbar mit einer ISBN-Nummer für ein Buch.
- Er dient der Identifikation, nicht der Lokalisierung.
- URNs sind besonders nützlich, wenn Ressourcen über lange Zeit eindeutig benannt werden sollen – unabhängig vom Speicherort.
Zusammenfassung: Vergleich Domain, URL, URI, URN
| Begriff | Definition | Beispiel | Abrufbar? | Typische Verwendung |
|---|---|---|---|---|
| Domain | Menschlich lesbare Adresse einer Webseite | www.beispielseite.de | Nein | Einstiegspunkt für Webseiten |
| URL | Vollständige Adresse einer abrufbaren Ressource im Web | https://www.beispielseite.de/index.html?id=123 | Ja | Webseiten, Bilder, Videos, APIs |
| URI | Allgemeine Kennung für eine Ressource – kann eine URL oder URN sein | mailto:info@beispielseite.de | Teilweise | Technische Identifikation im Web |
| URN | Dauerhafte, ortsunabhängige Kennung einer Ressource – kein Zugriffspfad | urn:isbn:978-3-16-148410-0 | Nein | Bibliotheken, Archive, eindeutige Namensräume |
Praxisbezug für Webentwicklung
- Beim Erstellen von Webseiten gibst du URLs für Bilder, Stylesheets oder Links an.
- Beim Hosting deiner Seite brauchst du eine Domain, damit sie erreichbar ist.
- Beim Arbeiten mit APIs oder Datenbanken begegnen dir oft URIs, z. B. zur Identifikation von Ressourcen.
Kommunikationsnetze
Server (deutsch: Bediener, Anbieter, Dienstleister, Bereitsteller, englisch: to serve) Ein Server ist ein Programm (Prozess), das mit einem anderen Programm (Prozess), dem Client (deutsch: Kunde), kommuniziert, um ihm Zugang zu einem Dienst zu verschaffen. Hierbei muss abgrenzend beachtet werden, dass es sich bei „Server“ um eine Rolle handelt, nicht um einen Computer an sich. Ein Computer kann nämlich ein Server und Client zugleich sein, siehe: Peer-to-Peer.
Client (deutsch: Kunde, Dienstnutzer) Ein Client kann einen Dienst bei dem Server anfordern, der diesen Dienst bereitstellt.
Protokoll / Kommunikationsprotokoll ist eine Vereinbarung, wie die Datenübertragung zwischen den beiden Parteien Server und Client abläuft.
Request (deutsch: Anforderung, Anfrage) Anforderung eines Clients an den Server, dessen Dienst er benötigt.
Response (deutsch: Antwort) Antwort eines Servers auf eine Anforderung eines Clients.
Ähnlich, jedoch nicht zu verwechseln sind die Ausdrücke „Daemon“ und „Service“. Mit beiden ist ein Programm gemeint, das im Hintergrund läuft. Ein Server ist immer auch ein Daemon. Jedoch gibt es Daemonen die Clients sind, beispielsweise ein Programm das automatisch Backups macht, oder die Zeit auf einem Computer automatisch einstellt (ntpd, network time protocol daemon). Genauso gut können Daemonen und Services mit niemand reden, also weder Client noch Server sein.
Protokolle
Ein Protokoll ist ein Regelwerk, das festlegt, wie zwei Systeme miteinander kommunizieren – z. B. ein Browser (Client) und ein Webserver. Ohne Protokolle wäre keine strukturierte Datenübertragung möglich. Damit diese Kommunikation zuverlässig funktioniert, werden die Aufgaben der Datenübertragung in Schichten organisiert – und genau hier kommt das OSI-Modell ins Spiel: Es beschreibt, wie Daten vom Sender zum Empfänger gelangen, Schritt für Schritt durch sieben klar definierte Ebenen.
OSI-Modell
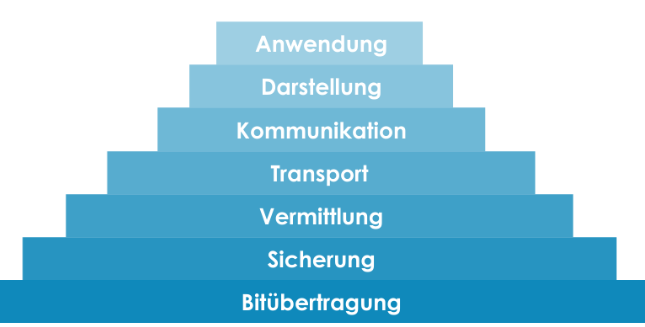
| Schicht | Funktion | Beispiel |
|---|---|---|
| 7. Anwendung | Benutzerinteraktion, z. B. Browser | HTML, HTTP, FTP |
| 6. Darstellung | Datenformate, Verschlüsselung | SSL/TLS, JPEG, MP3 |
| 5. Sitzung | Verbindungssteuerung | Login, Session-Handling |
| 4. Transport | Datenpakete, Fehlerkorrektur | TCP, UDP |
| 3. Vermittlung | Routing, IP-Adressen | IP, Router |
| 2. Sicherung | MAC-Adressen, Frames | Ethernet, Switch |
| 1. Bitübertragung | Physikalische Übertragung | Kabel, WLAN, elektrische Signale |
HTTP (Hypertext Transfer Protocol)
HTTP ist ein Standardprotokoll, das verwendet wird, um Webseiteninhalte vom Server zum Browser zu übertragen. Es regelt, wie Anfragen (z. B. „Zeig mir diese Seite“) und Antworten (z. B. „Hier ist der HTML-Code“) zwischen Client und Server ausgetauscht werden.
HTTPS (Hypertext Transfer Protocol Secure)
HTTPS ist die sichere Variante von HTTP. Sie verschlüsselt die Datenübertragung zwischen Browser und Server mithilfe von SSL/TLS. Dadurch sind sensible Informationen wie Passwörter oder persönliche Daten besser geschützt.
HTTP vs. HTTPS
- HTTP: Daten werden unverschlüsselt übertragen – potenziell unsicher
- HTTPS: Daten werden verschlüsselt übertragen – sicher und vertrauenswürdig
Moderne Webseiten verwenden fast ausschließlich HTTPS, erkennbar am Schloss-Symbol in der Adresszeile des Browsers.
FTP
FTP steht für File Transfer Protocol – also „Dateiübertragungsprotokoll“. Es ist ein Standardprotokoll, mit dem Dateien zwischen einem lokalen Computer (Client) und einem Server über das Internet übertragen werden können. FTP ermöglicht das Hoch- und Herunterladen von Dateien auf einen Webserver und wird häufig genutzt, um Webseiteninhalte wie HTML, CSS oder Bilder auf den Server zu übertragen.
Grundlagen HTTP-Statuscodes
Bei jeder Anfrage sendet der Server einen sogenannten Statuscode zurück. Die wichtigsten Codes:
200 OK– Alles funktioniert404 Not Found– Seite nicht gefunden500 Internal Server Error– Serverfehler Diese Codes helfen beim Verstehen von Fehlern und beim Debuggen.
Client und Server
- Client: Dein Browser, der eine Anfrage stellt
- Server: Das System, das die angeforderte HTML-Datei bereitstellt Du lernst die Rollenverteilung kennen und verstehst, wie HTML-Dokumente über das Web ausgeliefert werden.
Aufgabe
- Recherchiere IP-Adressen, welche Protokolle gibt es? Worin unterscheiden diese sich?
- Recherchiere den Begriff http & https? Worin unterscheiden diese sich?
- Recherchiere den Begriff FTP – was bedeutet er?
- Recherchiere den Begriff „Hoster“
- Recherchiere den Begriff „URI“ und „URL“ Worin unterscheiden sich diese?
- Was ist eine Subnetzmaske und welche Funktion hat sie im Zusammenhang mit IP-Adressen?
- Erkläre in eigenen Worten den Unterschied zwischen einer privaten IP-Adresse und der MAC-Adresse eines Geräts.
- Welche Auswirkungen hat die Verwendung eines VPN auf die öffentliche IP-Adresse eines Benutzers und welche Vorteile ergeben sich daraus für die Sicherheit?
Trage die Rechercheergebnisse im oben erstellten Arbeitsdokument „Webentwicklung_Unterrichtsblock_1.docx“ mit einer passenden Überschrift ein.
Technische Werkzeuge im Unterricht
Für die Webentwicklung brauchst du bestimmte Werkzeuge, um effizient und strukturiert arbeiten zu können. Visual Studio Code (VS Code) dient dir als Code-Editor, in dem du HTML, CSS, JavaScript und andere Sprachen schreibst. Mit Git kannst du deine Änderungen versionieren und nachvollziehbar machen. GitHub schließlich ist die Plattform, auf der du deinen Code online speicherst, mit anderen teilst und gemeinsam weiterentwickelst. Zusammen ermöglichen dir diese Tools eine professionelle, kollaborative und nachvollziehbare Projektentwicklung.
Wie du diese Werkzeuge einrichtest und nutzt, erfährst du hier: